Beyond agentic security scanning: Context files for toolless LLM analysis
Staff Engineer - Security Engineering
Frontier models are starting to dominate software security scanning. In fact, models are now strong enough at cybersecurity that providers now gate some workflows through verified access programs (OpenAI Trusted Access for Cyber, Anthropic Claude Mythos Preview through Project Glasswing). The important signal is not any single product launch, but the direction of travel: models are getting better at finding security issues in large, unfamiliar codebases.
The industry default is to expose those models through agentic coding tools. Give the model host access, let it search files and call tools, and trust it to decide when it has seen enough. That is a reasonable shape for general coding work and for tools that need to work generically across many codebases. For our codebase, we wanted to know whether we could do better. As models get stronger, the practical question becomes less "can the model understand this code?" and more "how do we maximize the model's performance on the security questions we care about?" Security review puts more pressure on completeness and reproducibility: if the model reads the wrong slice of code, stops too early, or fills its context window with exploration artifacts, the final report can look confident while resting on incomplete evidence.
So, we separated two jobs: context construction and model analysis. The rest of this post explains how we used compiler metadata to gather route-level context deterministically, package it into context files, and ask the model one focused security question over each fixed context. That completely eliminated the traditional agentic workflow as the model is used only for analysis and reasoning, not for deciding which files count as evidence.
The result was a scanning workflow with fixed inputs, repeatable prompt tests, no per-route host environment, and scaling governed mostly by API rate limits. More importantly, once every route has a context file, future security scans become trivial to define: the source has already been gathered, so each new scan is just a focused question over the right code in a single turn.
Case study: Insecure Direct Object References (IDORs)
We started with the obvious approach: ask an AI CLI to perform security scanning over the repository. IDOR detection was our first target because the bug is conceptually simple, but often hidden behind real application structure. The classic version is a user changing an ID in a URL and gaining access to data they do not own.
If the second request succeeds for a user who should only belong to organization 123, the route probably loaded an object by ID without proving that the current user was allowed to access it.
Status quo: How agentic harnesses work
A CLI scan looks like one request from the user's point of view, but the harness usually turns it into an agent loop. In this post, a model turn means one model invocation: input context goes in, an assistant response or tool request comes back. The loop creates multiple model turns, and each turn adds context and makes decisions before the analysis can finish.
Most of this is hidden from the user. The AI harness, commonly the local CLI, talks to the model over HTTP, executes requested commands, and feeds tool results back to the model. The user may only see the final response, unless a permission gate requires approval before a command runs. The loop looks roughly like this:
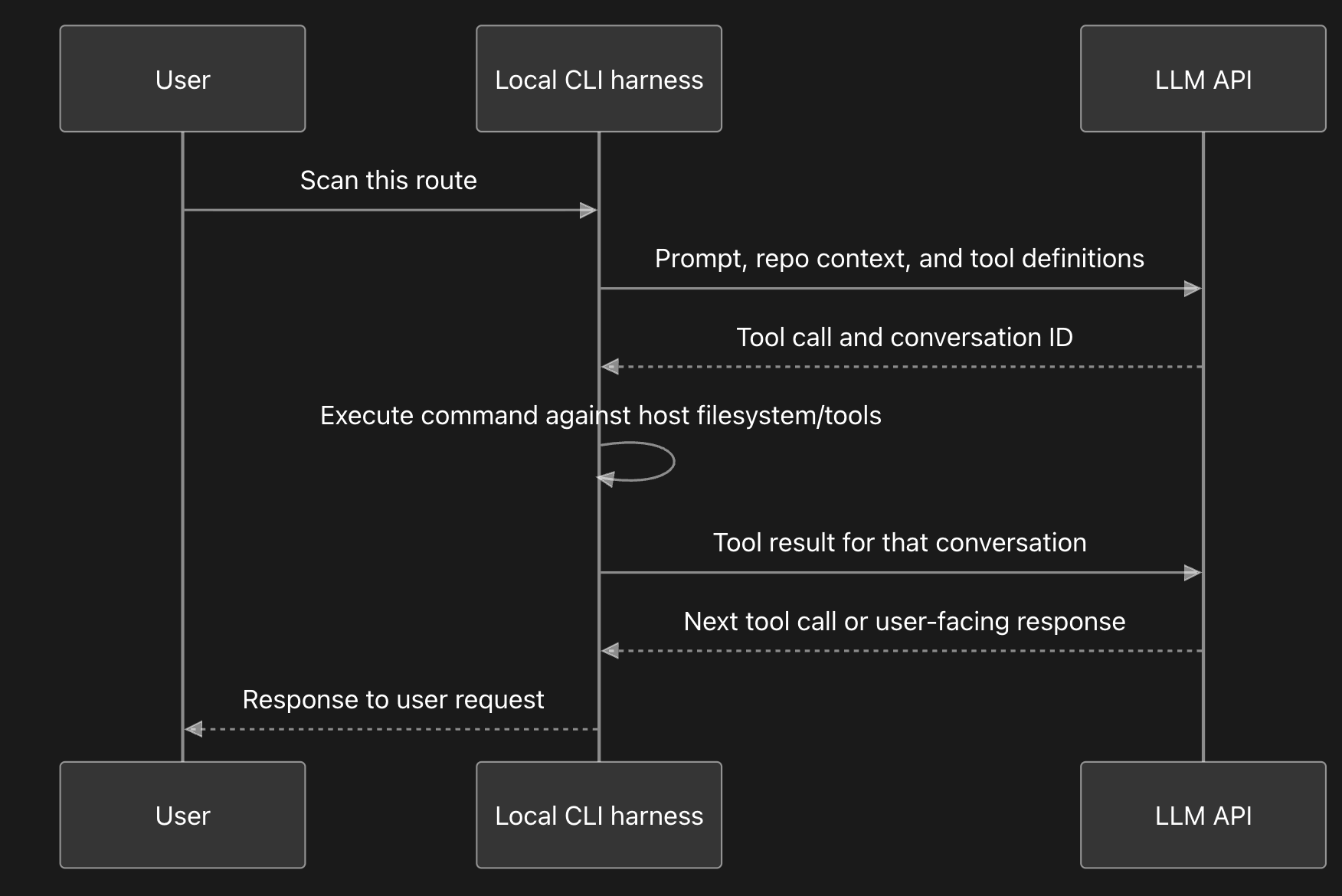
Every trip through that loop adds something to the model's working context. Before the model reads application code, the harness has already supplied the repository state such as the current working directory and a directory tree, plus tool definitions for shell commands and file reads. The exact schema varies by provider, but the beginning prompt looks something like this:
{
"messages": [
{ "role": "system", "content": "cwd: /repo\ndirectory_tree:\n- app/Handler.hs\n- app/Auth.hs\n- app/Drafts.hs\n- src/..." },
{ "role": "user", "content": "Scan this HTTP route for authorization bugs." }
],
"tools": ["shell"]
}The model then spends a turn deciding how to investigate. On later turns, it has to keep deciding what else to read, which paths still matter, and when it has enough evidence to stop:
{
"messages": [
{
"role": "assistant",
"reasoning": "I need to locate the route handler first. The directory tree points at app/Handler.hs, so I'll search for the handler name.",
"tool_calls": [
{
"name": "shell",
"arguments": { "cmd": "rg -n \"routeHandler\" ." }
}
]
}
]
}The next model call carries that conversation forward with the new tool result appended to the same message chain. Some providers expose this through a conversation ID, but conceptually the model is still being invoked against the growing thread:
{
"conversation_id": "conv_123",
"messages": [
{ "role": "system", "content": "cwd: /repo\ndirectory_tree:\n- app/Handler.hs\n- app/Auth.hs\n- app/Drafts.hs\n- src/..." },
{ "role": "user", "content": "Scan this HTTP route for authorization bugs." },
{
"role": "assistant",
"reasoning": "I need to locate the route handler first...",
"tool_calls": [
{
"name": "shell",
"arguments": { "cmd": "rg -n \"routeHandler\" ." }
}
]
},
{ "role": "tool", "content": "Handler.hs:214:routeHandler = ..." }
]
}For cost and latency, the useful mental model is that each new message replays the thread so far. The provider may store the thread behind a conversation ID, and repeated prefixes are cached at a lower input token price, but the model is still invoked against the accumulated prompt, prior messages, and newest tool result.
This is a problem because chat history keeps growing. This is one reason long agent sessions can feel worse over time: junk accumulates, and the model has to keep contending with it. By the time we get a final answer, the context is no longer just code; it also contains directory listings, tool schemas, searches, partial snippets, failed leads, tool outputs, and earlier assistant messages.
That matters because long-context models do not use every token equally well. Lost in the Middle found that performance can degrade when relevant information is buried inside long prompts, and Chroma's Context Rot report found that model behavior grows less reliable as input length increases.
Sub-agents are one common way to manage this. Instead of keeping everything in one growing thread, the main agent can hand a focused prompt to another agent and then read back its result. For this problem, that could mean one agent gathers route context and a second agent performs the security analysis. That protects the second agent from the first agent's context rot, but it does not solve determinism or incompleteness. The analysis agent still relies on the code slice chosen by the context-gathering agent, whose own view of the codebase was shaped by tool calls, partial reads, and intermediate reasoning.
The better way: Building context files for our codebase
In order to cut the non-deterministic context-gathering step we need to craft files containing the universe of code that we wanted to analyze. For our Haskell backend, that meant turning each public HTTP route into a deterministic "context file": a bundle of source code that defines an entire HTTP route, including the dependencies reachable from its handler, as a single file.
A context file does not compile and may not even be syntactically complete, but it is still readable to an LLM because it is made of function definitions and surrounding code. The context gathering program starts at the handler, follows the declarations it can reach, extracts the source spans for those declarations, and concatenates them into the bundle the model reviews.
The division of labor was explicit:
- The deterministic context gathering program builds a reproducible context file for each route.
- The AI model reads the context file and answers the security question.
Context gathering: The shape of a route
For most security reviews, the question starts with user input: where does it enter, where can it flow, and what sensitive operation does it eventually reach? A useful route-level context file needs enough code to distinguish raw user input from input that has already been constrained, scoped, authorized, or transformed.
This is where partial exploration hurts. A model can see a path parameter flow into a database helper, stop before the sanitizer or authorization helper, and report a vulnerable route even though the missing helper is exactly what makes the route safe.
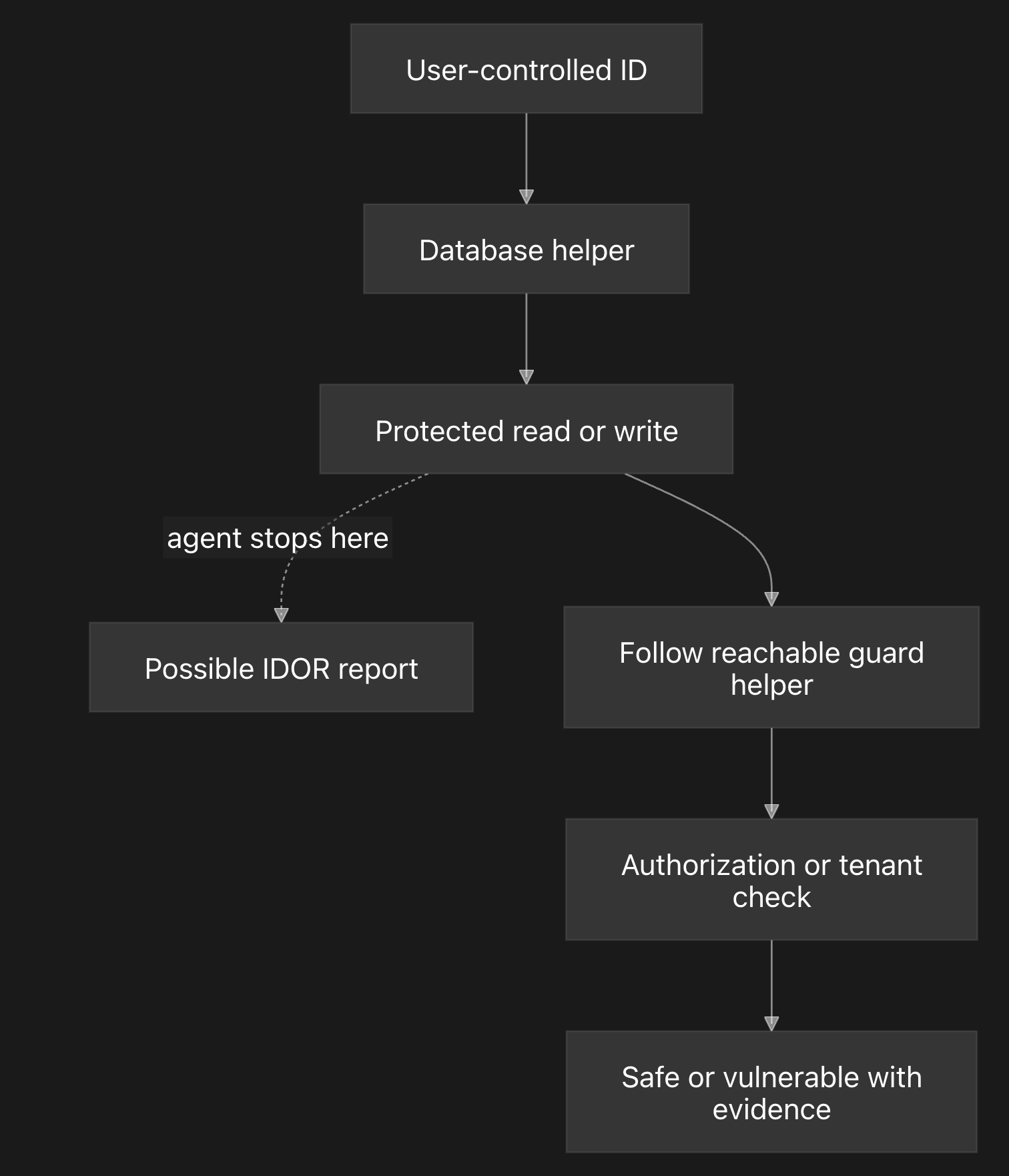
For IDOR specifically, the source is usually a user-controlled ID and the sink is a protected read or write. The model can reason about whether the path is safe only if it sees the code between those points: parser helpers, typed route parameters, authorization checks, tenant scoping, database helpers, and any business logic that changes how the ID is used.
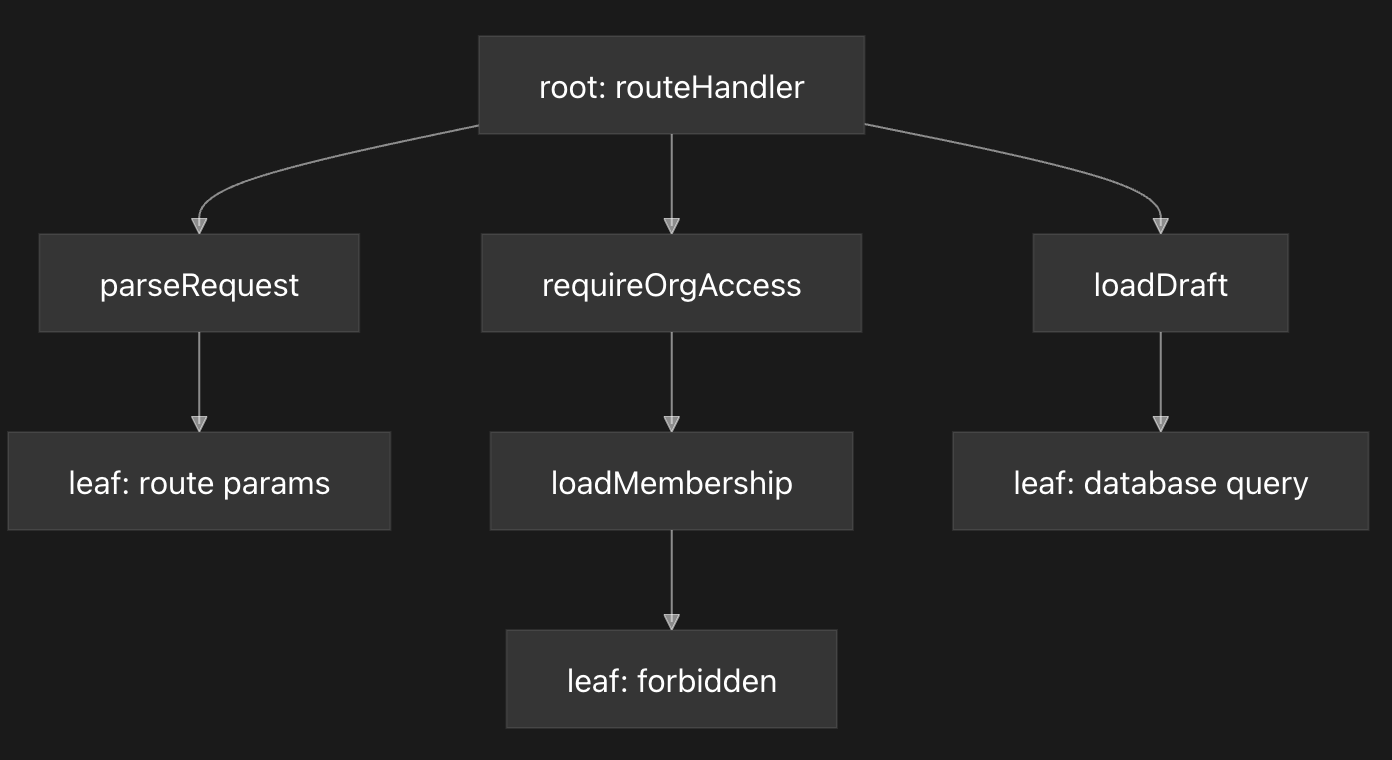
This is a trivial reachability problem: given a root function, collect the functions it can call, then the functions they can call, and continue until we hit the leaves. Once traversal finishes, we have reconstructed the route's call graph as source code and created the basis for a context file.
Using compiler metadata
The route shape told us what graph we wanted. To build that graph from source code, we needed two kinds of compiler metadata:
- Declaration locations: where each function lives in the source tree.
- Reference edges: which declarations refer to which other declarations.
Haskell gave us both:
- GHC can emit .hie files when compiled with
-fwrite-ide-info; those files persist IDE metadata such as declarations, references, module information, symbol names, and source spans. - The hiedb tool loads that metadata into a SQLite database and can perform the graph traversal for us through its built-in
reachablecommand.
Conceptually, hiedb reachable did what we wanted: for a starting symbol like routeHandler, return the symbols reachable from that root. For the full scan, we kept that behavior but changed where the graph was built. Instead of computing reachability as a standalone operation for each route, we exported the whole-codebase graph once and traversed it ourselves per route. To do so we followed these steps:
- Compiled with
-fwrite-ide-info. - Loaded the
.hiefiles intohiedb. - Exported declarations as graph nodes, including module names, file paths, symbols, and source spans.
- Exported references as graph edges from caller to callee.
- Built an in-memory adjacency list once.
- Traversed the graph from each HTTP route handler.
Once the graph was built, each route was just a breadth-first collection, which brought the full-codebase reachability step down to roughly five minutes. You can imagine running this program in CI/CD so every build produces an up-to-date node and edge database for the codebase.
Graph traversal does not immediately produce the final context file. First, it produces a compact manifest of the declarations reachable from one route handler. Each row contains the module, symbol, and source span needed to recover the function definition:
("App.Drafts",".hiefiles/App/Drafts.hie","v:loadDraft",42,1,57,54)The context gathering program then resolves the module to the source file and reads from line 42 column 1 through line 57 column 54. That source slice is the function definition:
loadDraft organizationId =
queryOne "select * from drafts where organization_id = ?" [organizationId]The final context file is the concatenation of those reachable source definitions. It is not a valid module and does not compile, but it works well for AI analysis because the model can understand the relevant function bodies without needing the compiler boilerplate. It is the model's working set: the first-party source code reachable from one public entrypoint.
Shrinking context files without losing determinism
After going through the generation process we inspected the context files and noticed that they contained extra definitions which were not impactful to security analysis. As mentioned before, the more tokens included in the input the worse results we would expect. On top of that, we do not want the model spending time evaluating functions which we know will not impact security.
Slack routing, metrics, logging, tracing, and other non-control-flow metadata were still reachable from the handler, so the deterministic graph included them even though they rarely affected the security question. Because every declaration had a start and stop row, we could inspect the generated files, estimate which functions were consuming the most tokens, and prune the largest low-value functions directly.
After pruning, the per-context-file input-token distribution looked like this:
Percentile | Input tokens |
|---|---|
P25 | 14,640 |
P50 | 18,572 |
P75 | 28,021 |
P90 | 62,612 |
P95 | 97,562 |
P99 | 214,297 |
Most routes fit comfortably inside modern context windows. The long tail still mattered, but every route could fit within a 1M-token context window model if necessary.
Fixed-context route analysis
With stable context files built up front, analysis became a simple handoff. Context gathering program writes the route file, and the analysis program submits that file with the review prompt in one HTTP call.
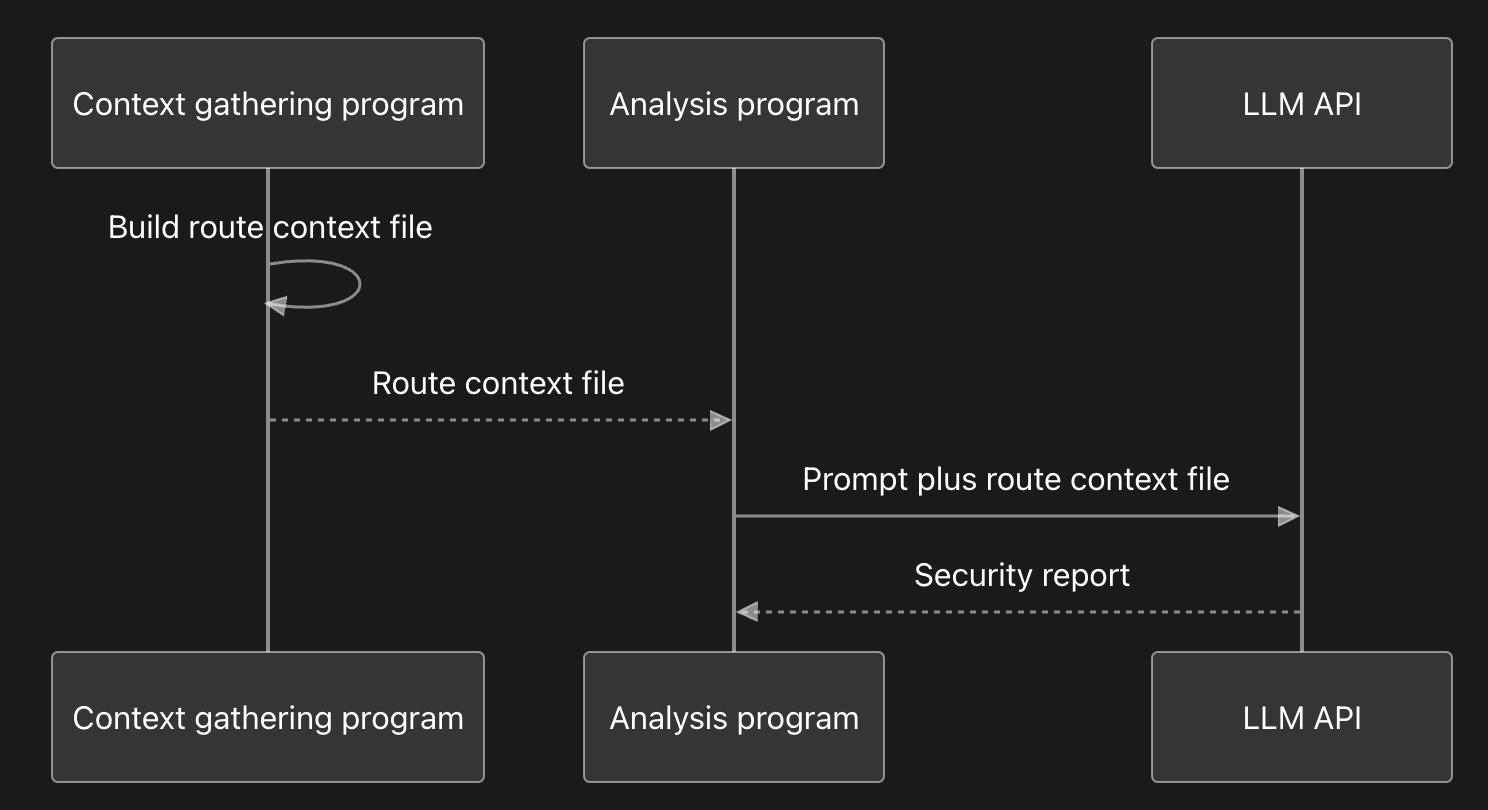
For example, the request payload looks like this:
{
"messages": [
{
"role": "system",
"content": "Review this route for authorization bugs. Cite the relevant evidence."
},
{
"role": "user",
"content": "<route-context-file>"
}
]
}where <route-context-file> is the code slice generated for that route:
routeHandler currentUser organizationId = do
draft <- loadDraft organizationId
requireOrgAccess currentUser organizationId
pure draft
requireOrgAccess user organizationId = do
membership <- loadMembership user.id organizationId
when (isNothing membership) forbidden
loadDraft organizationId =
queryOne "select * from drafts where organization_id = ?" [organizationId]Compared to the multi-turn model, the request is smaller and more bounded. The context gathering program has already decided which code belongs in the review, so the model's input is the prompt plus route code. Thus, our system has these properties:
- No CLI harness or live file system needs to inject cwd, directory trees, tool definitions, or file-read scaffolding into the context window.
- No sandboxes, repository mounts, agents, or tool loops need to run during analysis.
- Each route becomes one independent HTTP request to the model provider.
- With unlimited concurrency and no rate limits, the full scan would take as long as the slowest single route analysis; in practice, wall-clock time is governed by API rate limits.
- The async flow fits provider batch APIs. OpenAI's Batch API and Anthropic's Message Batches API support bundles of independent requests with discounted pricing compared to standard synchronous calls. CLI agents are a poor fit for that model because each route review is an interactive chain of dependent turns; single-turn route analysis is naturally batchable as one JSONL row per route.
A/B testing prompts
Stable context files made prompt iteration easily comparable. In earlier tests with agent CLIs, one run might read a helper, another might miss it, and a third might collect different surrounding context. When the output changed, we could not tell whether the prompt improved or whether the agent had simply made different exploration choices. With the input held constant, we could change the prompt and measure the effect more reliably.
For our own case we evaluated the prompt against known bug bounty reports and internal findings. For a historical vulnerability, we checked out the vulnerable commit, generated the route's context file from that version of the code, and asked the model to find the issue. If it missed, we inspected where the reasoning went wrong and tightened the prompt.
Three prompt choices mattered most:
- Lean into focus. In security review, the focus should generally be on user input and how it flows through the program. Models tend to return to whatever the prompt emphasizes, so when the model started wandering into unrelated helpers, the prompt pulled it back toward how request inputs were used.
- Require evidence first. The model had to cite the handler, input parsing, database calls, and apparent authorization checks before writing its conclusion.
- Classify suspicious-but-intentional patterns separately. Secret tokens, unguessable IDs, and intentional capability-style flows should not be treated the same as changing an
org_idin a request.
The battle-tested final prompt came from concrete corrections to real examples.
Beyond IDOR
Per-route context files are useful for more than only IDOR review because the single-turn pattern is general. Once we can deterministically slice a codebase by entrypoint, we can ask other focused questions without giving the model host access:
- Which reachable database operations should be in one transaction but are split across several?
- Which third-party service calls lack clear timeout or failure handling?
- Which sensitive state changes lack structured logging?
- Where do sensitive routes rely on inconsistent authorization patterns?
The limiting step becomes consolidation across many route-level answers rather than context collection for each individual answer.
The same pattern also works outside Haskell if the language ecosystem exposes enough metadata. Compilers, language servers, and static analyzers often already know where declarations live and which symbols reference which other symbols. The implementation details will vary, but the strategy is portable: build a deterministic graph, slice by entrypoint, and ask a narrow question over the slice.
What the full scan found
We ran the analysis across more than 1,200 user-facing HTTP routes with 250 concurrent API requests. The results were encouraging:
- Model cost was $178.90 using GPT-5 pricing at the time: roughly $78 for input tokens and $100 for output tokens.
- The model flagged 13.6% of routes as potentially vulnerable.
- We reviewed and addressed the findings, with roughly 50% turning out to be real security issues or code paths we were comfortable changing.
- Most false positives came from misunderstanding our domain model or poor model reasoning rather than missing route context.
- The reports included the snippets the model relied on, so reviewers could usually decide quickly whether a finding was valid.
The observed true-positive or change-worthy rate was high enough to make the triage burden practical. One validated authorization issue would have justified the scan on its own as a comparable bug bounty report would have cost us more than the full model run.
All security issues identified through this process were fixed before publication.
About the author
Staff Engineer - Security Engineering
Tags
Share article
Related reads

