8 Lints for your Postgres schema
Max Tagher is the co-founder and CTO of Mercury.
Over six years at Mercury, I’ve collected some good practices to enforce on your database schema. This is the code I’d most recommend other companies consider using — it’s generic, only added after experience, and so much easier to have implemented from the get-go. For each lint, I’ve included the Postgres-flavored SQL that drives it, but you’ll probably want to convert the SQL to a test that gives clear error messages.
Correctness
All tables should have primary keys
It’s totally possible to make a table without a primary key, but you probably never want to do that. Before Mercury wrote the test below, we had four tables that were unintentionally missing primary keys.
Luckily for us, these missing keys didn’t have catastrophic consequences, since the tables had a unique constraint on a foreign key column that was logically equivalent to a primary key. The worst that happened was an error when we started syncing data to a separate database for our data science team. But you might not always be so lucky, so as a matter of hygiene, I recommend having a primary key on every table.
Here’s how to get a list of tables that are missing a primary key in Postgres:
SELECT relname FROM pg_class pgc
JOIN pg_namespace pgns ON pgns.oid = pgc.relnamespace
WHERE pgns.nspname = 'public'
AND pgc.relkind = 'r'
AND pgc.oid NOT IN
(SELECT pgc.oid
FROM pg_class pgc
JOIN pg_index pgi ON pgi.indrelid = pgc.oid
JOIN pg_namespace pgns ON pgns.oid = pgc.relnamespace
WHERE pgi.indisprimary = true
AND pgc.relkind = 'r'
AND pgns.nspname = 'public'
);Just put this into a test and confirm it returns zero results, and you’re good!
(In order to keep this blogpost a reasonable length, I’m not going to explain how each SQL snippet works. But if you’re interested, Postgres has docs on all of these metadata tables).
Database timezone in UTC
Ok, so this isn’t actually a schema lint, but you’re likely to get weird behavior when a developer’s local Postgres is on their local timezone instead of UTC. It’s much easier to catch this with a test for the correct timezone than trying to debug the broken code it causes. Simply run this SQL in your tests and confirm it returns UTC:
SHOW TIMEZONE;As part of the test failure message, suggest updating postgres.conf (to change all databases) or running ALTER DATABASE db_name SET TIMEZONE TO 'UTC';.
Immutable columns
If your data science team asked you “Hey, can the created_at field ever change?” or “Do we ever change the customer a transaction is associated with?”, you’d probably say, “No, that can never happen”—with just a thought in the back of your mind that, somewhere across your hundreds of thousands of lines of code, some nasty little bug is lurking to prove you wrong.
At Mercury, such a bug reared its head when some errant code began updating the created_at field of our api_tokens table to the current time (a repsert gone wrong). Our graph of “API tokens created per week” was based on the created_at field, so it looked like we were suddenly creating thousands of new tokens per day, and that we potentially had a critical security vulnerability on our hands.
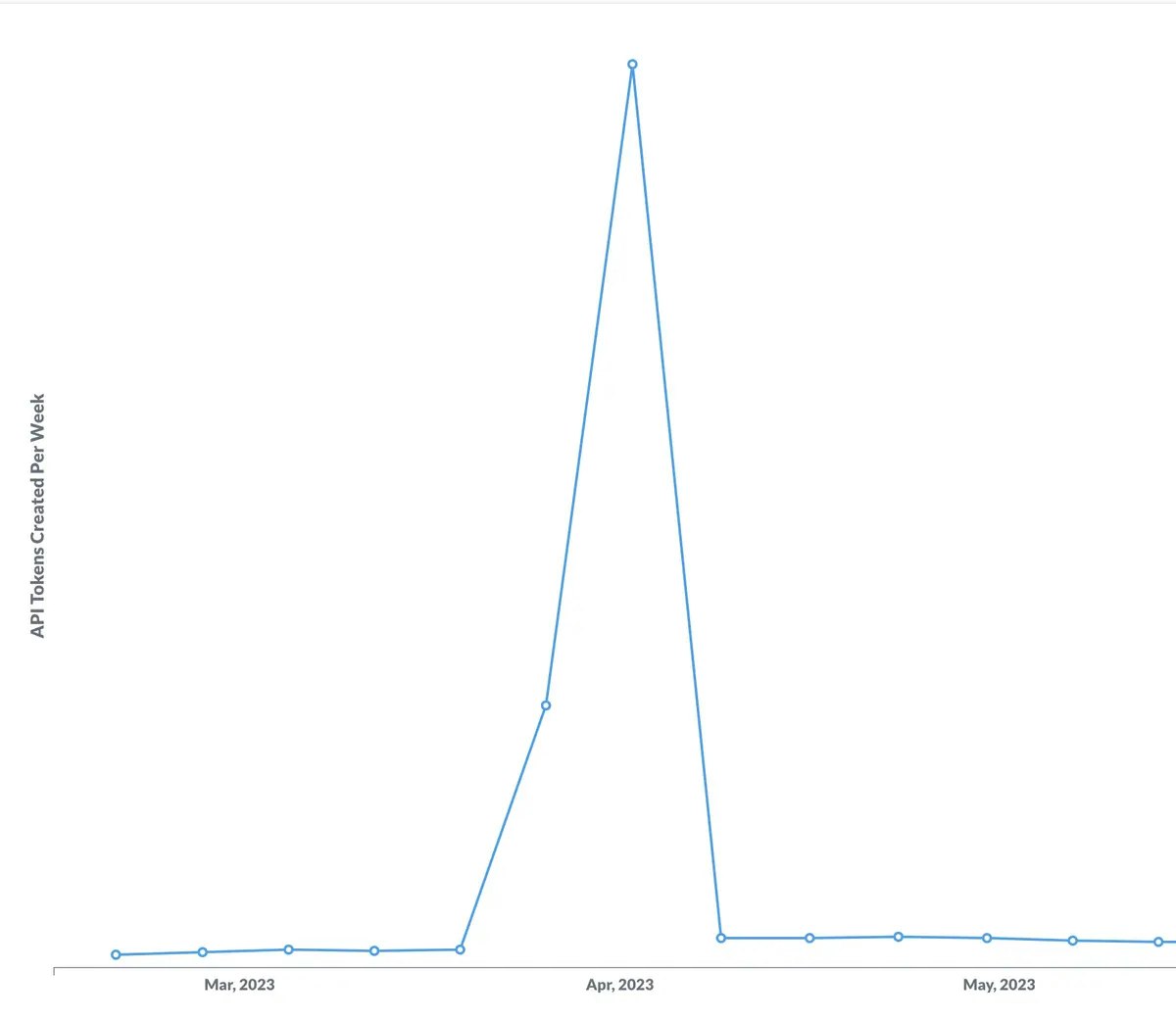
Because we were working off the precondition that created_at couldn’t change, our graph wasn’t telling us what we thought it was, and it took us a while to realize what was going on. What’s more, we lost the timestamp of when an API token was actually created.
One way to prevent something like this would be to enforce that certain database columns can’t change, either via database permissions or triggers.
Enforcing immutability with triggers
Here’s a sketch of how you might do this with triggers. First, label which fields are mutable in your ORM (or immutable—the default's your choice):
Transaction
amount Dollar
account_id MercuryAccountId
created_at UTCTime
updated_at UTCTime !mutable -- Only this column can changeNext, write code to map from your ORM's perspective to auto-generate this SQL:
CREATE TRIGGER immutable_columns
AFTER UPDATE OF amount, account_id, created_at ON transactions -- It's more efficient if we make sure columns are listed here, so we can in practice avoid the WHEN condition from having to be run
FOR EACH ROW
WHEN
(( OLD.amount IS DISTINCT FROM NEW.amount
OR OLD.account_id IS DISTINCT FROM NEW.account_id
OR OLD.created_at IS DISTINCT FROM NEW.created_at
)
EXECUTE FUNCTION raise_immutability_exception();
CREATE OR REPLACE FUNCTION raise_immutability_exception() RETURNS trigger AS
$$
BEGIN
RAISE EXCEPTION 'This update was rejected because it attempted to UPDATE an immutable column. Old data: % -- New data: %', OLD, NEW
USING HINT = 'Tip: check the triggers on the table to see what columns are immutable. repsert-esque functions are a common cause of this bug.';
END
$$
LANGUAGE PLPGSQL;Instead of auto-generating the SQL above, you can write a function to turn the above into a one-liner function call:
CREATE OR REPLACE FUNCTION set_immutable_columns(VARIADIC table_and_columns text[])
returns void
as $$
declare
table_name text;
columns text[];
column_list text;
column_condition text;
begin
if array_length(table_and_columns, 1) < 2 then
raise exception 'Pass at least a table and one column to set_immutable_columns, eg set_immutable_columns(''table'', ''col1'', ''col2'')'
using detail = format('Arguments received: %s', table_and_columns);
end if;
table_name := table_and_columns[1]; -- one indexed (heathens!), so first element
columns := table_and_columns[2:];
column_list := array_to_string(columns, ', ');
column_condition := ( SELECT string_agg(x.y, ' OR ') FROM (SELECT '(OLD.' || col || ' IS DISTINCT FROM NEW.' || col || ')' as y FROM unnest(columns) AS col) as x );
EXECUTE format(
'CREATE OR REPLACE TRIGGER immutable_columns
AFTER
UPDATE OF %s
ON public.%s
FOR EACH ROW
WHEN (%s)
EXECUTE FUNCTION raise_immutability_exception ();'
, column_list
, table_name
, column_condition
);
end;
$$
language plpgsql;
-- Now this one line function call is available:
SELECT set_immutable_columns('transactions', 'amount', 'id', 'created_at');Finally, use SQL in your test suite to confirm the triggers are in place:
-- Get tables that have a trigger called immutable_columns
SELECT pgc.relname,
pgp.proname,
pgt.tgattr,
pgt.tgtype,
pg_get_triggerdef(pgt.oid) as triggerdef
FROM pg_trigger pgt
JOIN pg_class pgc ON pgc.oid = pgt.tgrelid
JOIN pg_proc pgp ON pgp.oid = pgt.tgfoid
WHERE tgname = 'immutable_columns';-- Extra credit: Get a list of columns by attnum to confirm the correct ones are listed in the WHEN condition
SELECT pgc.relname,
pga.attname,
pga.attnum
FROM pg_trigger pgt
JOIN pg_class pgc ON pgc.oid = pgt.tgrelid
JOIN pg_attribute pga ON pga.attrelid = pgc.oid
WHERE tgname = 'immutable_columns';You’ll need to do a little work in the test suite to ensure everything is set up correctly. Your test code should look at the tables that have the immutable_columns trigger and check they match what is expected by your ORM. You can use pg_get_triggerdef to check the WHEN clause, and use the second query above to check the UPDATE OF part.
Should you need to temporarily update those immutable columns, like in a test, you can disable triggers with SET session_replication_role = replica;.
There is some performance overhead to this trigger, but it’s likely negligible since Postgres would only need to check once per statement to see if immutable columns are modified.
Enforcing immutability with permissions
Instead of triggers, you can accomplish a similar thing with permissions:
GRANT UPDATE (updated_at, mutable_column_here) ON tablename TO "database-username";Permissions feel like the more principled solution to me, but:
- The error messages for permission are a little worse:
"ERROR: permission denied for table tablename" - Internally we're more comfortable with triggers
- It was easier to disable triggers in our test suite than open a database connection under a new user to mutate normally-immutable fields.
But the permission approach might make sense for you!
Immutability conclusion
Enforcing immutability is only sort of a lint, it’s more involved to set up, and is still at an experimental stage at Mercury. Treat this one as an interesting idea to consider, not as something I’m confidently recommending.
There’s a lot more to write about this, but hopefully the above gives you enough to go off of!
Blocking deletes on a table
Just like with immutable columns, you probably have an assumption that some tables can’t have rows deleted from them—and that assumption is either key to your code’s logic or essential for fulfilling your data retention policies.
Just like with the above, you could implement a similar system to block DELETE on certain tables, and enforce it in the same way (via permissions or triggers).
CREATE OR REPLACE FUNCTION raise_undeletable_table_exception() RETURNS trigger AS
$$
BEGIN
RAISE EXCEPTION 'DELETE is not allowed on this table';
END
$$
LANGUAGE PLPGSQL;
CREATE TRIGGER undeletable_table
AFTER DELETE ON transaction_metadata
FOR EACH STATEMENT
EXECUTE FUNCTION raise_undeletable_table_exception();You would use similar SQL as we did for immutable columns to confirm these triggers are on the right tables, but it should be a lot simpler because individual columns aren’t involved.
Timestamps
Having timestamp columns (created_at, updated_at, and in some cases deleted_at) is a great way to debug production systems, and you often need the data for user-facing pages anyway. I recommend requiring that created_at and updated_at columns exist on every table, and that triggers exist to update them appropriately (you don’t want to rely on your ORM to update these à la Ruby on Rails—ORM triggers won’t fire on raw SQL).
Below, you’ll find some SQL to check created_at and updated_at exist on all your tables. This SQL will return any tables that are missing a created_at or updated_at column. Just check to make sure the query returns no rows:
with all_tables as (
select
t.table_name,
exists (
select from information_schema.columns c
where c.column_name = 'created_at'
and c.table_name = t.table_name
and c.table_schema = t.table_schema
) as has_created_at,
exists (
select from information_schema.columns c
where c.column_name = 'updated_at'
and c.table_name = t.table_name
and c.table_schema = t.table_schema
) as has_updated_at
from information_schema.tables t
where
t.table_schema not in ('information_schema', 'pg_catalog')
and t.table_type = 'BASE TABLE'
)
select * from all_tables
where
not has_created_at
or not has_updated_at
order by table_name;But it’s not enough to check that created_at and updated_at columns exist—you also need to set and update them correctly. This SQL creates the functions to do that:
create or replace function create_timestamps()
returns trigger as $$
begin
new.created_at = now();
new.updated_at = now();
return new;
end $$ language 'plpgsql';
create or replace function update_timestamps()
returns trigger as $$
begin
new.updated_at = now();
return new;
end $$ language 'plpgsql';Then add the triggers on each table:
CREATE TRIGGER table_name_insert
BEFORE INSERT ON table_name
FOR EACH ROW EXECUTE PROCEDURE create_timestamps();
CREATE TRIGGER table_name_update
BEFORE UPDATE ON table_name
FOR EACH ROW EXECUTE PROCEDURE update_timestamps();Optionally, you can use a create a function to simplify adding timestamp columns and triggers:
CREATE OR REPLACE FUNCTION add_timestamp_columns (table_name text)
RETURNS void
AS $$
BEGIN
EXECUTE format('ALTER TABLE %I ADD COLUMN IF NOT EXISTS created_at TIMESTAMPTZ NOT NULL;', table_name);
EXECUTE format('ALTER TABLE %I ADD COLUMN IF NOT EXISTS updated_at TIMESTAMPTZ NOT NULL;', table_name);
EXECUTE format('CREATE OR REPLACE TRIGGER %I_insert BEFORE INSERT ON %I FOR EACH ROW EXECUTE PROCEDURE create_timestamps();', table_name, table_name);
EXECUTE format('CREATE OR REPLACE TRIGGER %I_update BEFORE UPDATE ON %I FOR EACH ROW EXECUTE PROCEDURE update_timestamps();', table_name, table_name);
END;
$$
LANGUAGE plpgsql;
-- Now this one line function call is available:
SELECT add_timestamp_columns('table_name');Finally, wrap it up with some SQL that checks whether or not these timestamp triggers exist on the tables. Make sure this SQL returns no rows:
WITH tables_with_trigger AS (
SELECT pgcl.*
FROM pg_class pgcl
JOIN pg_namespace pgns on pgns.oid = pgcl.relnamespace
LEFT JOIN pg_trigger pgtg ON pgtg.tgrelid = pgcl.oid
LEFT JOIN pg_proc proc ON proc.oid = pgtg.tgfoid
WHERE pgns.nspname = 'public'
AND relkind = 'r'
AND proc.proname = 'create_timestamps'
AND pgtg.tgenabled <> 'D'
)
SELECT pgcl.relname FROM pg_class pgcl
JOIN pg_namespace pgns on pgns.oid = pgcl.relnamespace
LEFT JOIN tables_with_trigger twt ON twt.oid = pgcl.oid
WHERE twt.oid IS NULL
AND pgns.nspname = 'public'
AND pgcl.relkind = 'r'
AND EXISTS (
SELECT FROM information_schema.columns c
WHERE c.column_name = 'created_at'
AND c.table_name = pgcl.relname
AND c.table_schema = pgns.nspname
);
-- For updates, run the same SQL above, but swap in 'update_timestamps' + 'updated_at'Documentation
Requiring comments on every table
Writing documentation is an easy, scalable way to share knowledge within your company. It’s usually difficult to have hard-and-fast rules about what to document, but database models are so critical and used by so many non-engineering teams that requiring documentation via linting is an easy call to make.
At Mercury, we document tables and columns in our ORM code, which is nice because the comments are editable, searchable, and in source control. Using our ORM persistent, we can get a list of all models and loop through them, calling getEntityComments to see if every table has documentation. If not, we fail the test.
You could potentially go further by requiring every column to have documentation, but this might create too many useless comments (“created_at is when the row was inserted”).
At Mercury, we also require comments on every enum that is used in our database. Exactly how this happens is a little complex and Haskell-specific, but, you can get good ROI out of requiring documentation on these, as they usually carry a lot of semantic value.
Regardless, once you have this information, you can propagate it to other places. We have two important places we propagate comments to:
1. We have the equivalent of a cron job that copies the comments into Postgres itself, like so:
COMMENT ON TABLE my_schema.my_table IS 'Employee Information';
COMMENT ON COLUMN my_table.my_column IS 'Employee ID number';
COMMENT ON TYPE an_enum IS 'List each enum case and docs here';These comments show up when you run \d+ table_name, and can be used by database GUI tools like Metabase.
2. We generate a file called schema.html via a Github Action. This file makes it easy for people to see our entire schema in one command+f-able place, especially non-engineering teams like data science and product.
All tables present in seed data
Many companies have a concept of sample (“seed”) data for a development database that comes pre-loaded with rows so you aren’t starting from scratch. This is helpful for new hires, but it’s also nice for existing hires so that they don’t have to worry about their database getting in a bad state or retaining the data across database upgrades.
How you generate seed data is up to you, but I’d recommend having some sort of command-line interface for your app that can use your domain models to generate data.
Once you have such a script, your challenge is making sure new tables are represented in the seed data. You can automate this by just checking that every table in your database has data in it after running the script. We iterate through every table our ORM knows of and run this SQL to check if a row exists in the table:
SELECT true FROM tablename LIMIT 1;In practice, you’ll have some cases where seed data isn’t helpful (e.g. a fake API key in your database would just be misleading). To solve that, you can have a list of tables permanently exempt from this check. At Mercury, we also have a list of temporarily exempt tables and the date they were exempted, so people can skip this check and add the data later, but I’m not confident temporary exemptions are a good practice.
Performance
Indexes on foreign key constraints
Foreign key constraints are a great way to keep your database consistent. When you have a parent table foreign keyed to by a child table, the column on the parent table must be a primary key or have a unique constraint, and thus is automatically indexed.
But the reverse direction is not required to have an index, so child.parent_id might not have an index.
In some cases this is totally fine, like if you just INSERT into both tables. But what if you DELETE from the parent table? In that case, Postgres needs to check if the child table has rows that foreign key to the parent to make sure a constraint isn’t violated. Without an index, that implies a full table scan on child.parent_id.
Further, if you DELETE CASCADE, a grandchild table referencing the child table needs to have an index on its child_id column to allow for an efficient lookup.
Here’s the SQL to recursively check if everything referencing the parent has an index on that column. This SQL works from a fixed list of deletableTables, but you could also get the list dynamically by labeling in your ORM which tables allow DELETE, as mentioned above. This SQL also allows you to exclude some tables from needing an index, via excludedReferencingTables.
-- Replace the values inside %{NE.fromList ...} with your own data
WITH RECURSIVE
fkey_constraints AS (
SELECT oid, conrelid, conkey, confrelid
FROM pg_constraint
WHERE contype = 'f'
),
deletable_fkey_constraints AS (
SELECT oid, conrelid, conkey
FROM fkey_constraints
WHERE confrelid::regclass::text IN %{NE.fromList deletableTables}
UNION ALL
SELECT c2.oid, c2.conrelid, c2.conkey
FROM deletable_fkey_constraints c1
JOIN fkey_constraints c2 ON c1.oid <> c2.oid AND c1.conrelid = c2.confrelid
WHERE c1.conrelid::regclass::text NOT IN %{NE.fromList excludedReferencingTables}
),
deletable_fkey_constraints_distinct AS (
SELECT DISTINCT conrelid, conkey
FROM deletable_fkey_constraints
)
SELECT CASE WHEN a.attnotnull THEN 'CREATE INDEX CONCURRENTLY IF NOT EXISTS ' || c.conrelid::regclass::text || '_' || a.attname || '_idx' || ' ON ' || c.conrelid::regclass::text || ' (' || a.attname || ');'
ELSE 'CREATE INDEX CONCURRENTLY IF NOT EXISTS ' || c.conrelid::regclass::text || '_' || a.attname || '_idx' || ' ON ' || c.conrelid::regclass::text || ' (' || a.attname || ') WHERE ' || a.attname || ' IS NOT NULL;'
END AS missing_index
FROM deletable_fkey_constraints_distinct c
CROSS JOIN LATERAL UNNEST(c.conkey) ak(k)
INNER JOIN pg_attribute a ON a.attrelid = c.conrelid AND a.attnum = ak.k
LEFT JOIN pg_index ix ON ix.indrelid = c.conrelid
AND ix.indkey[0] = ak.k
AND ix.indisvalid
AND (ix.indpred IS NULL OR NOT a.attnotnull) -- allow partial index if attribute is nullable
-- ideally we would make sure it's just attribute IS NOT NULL
WHERE ix IS NULL
ORDER BY c.conrelid::regclass::text, a.attname;Even more lints
Before I wrote this blog post, I didn’t even think of these as “lints”, but the process of doing so led me to find Kristian Dupont’s schemalint project. This tool has additional lints you might benefit from, like:
- Checking for
VARCHARvsTEXT- (
TEXTis stored as a binary blob in MySQL, soVARCHARis preferred there, but in Postgres they’re synonyms)
- (
- Checking whether you used the correct casing for column names
- Checking you’ve used
jsonbinstead ofjson
Check out the full list of lints here.
Conclusion
Unlike most tests, the lints above have wide reach, and unlike most lints, the ones in this post are impactful and best adopted early. I encourage you to identify the ones that seem most salient for your company, be it ensuring that new tables show up in seed data or requiring comments on all new database tables, and sharing those ideas with your team.
License: Some of the code snippets above are fairly long, but please feel free to use them verbatim in your own work. Consider them hereby released under CC-Zero.
Thanks to Sebastian Bensusan, Janey Muñoz, and Micah Fivecoate for reviewing this post.
About the author
Max Tagher is the co-founder and CTO of Mercury.
Share article
Related reads

